Local-First AI Governance
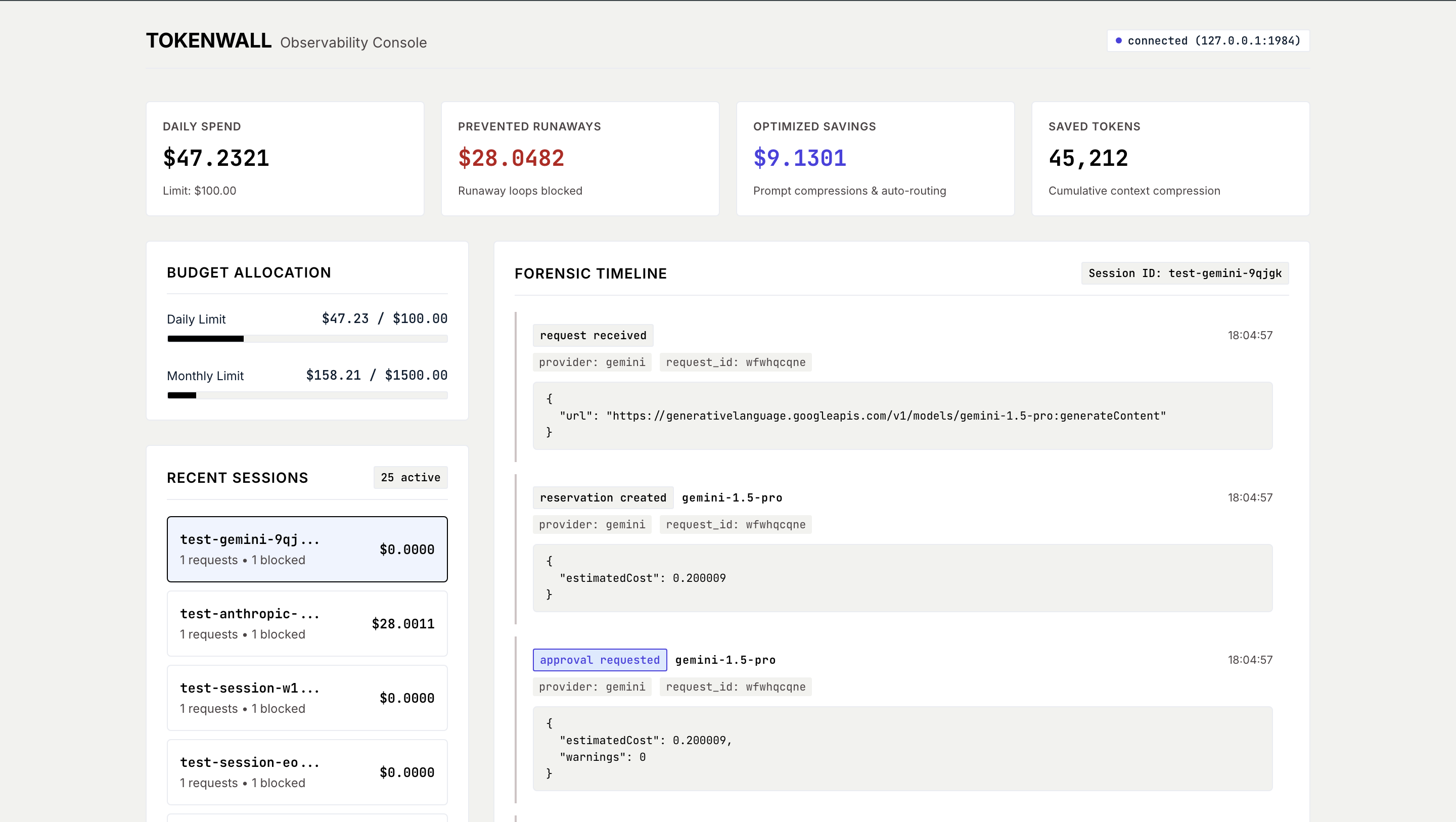
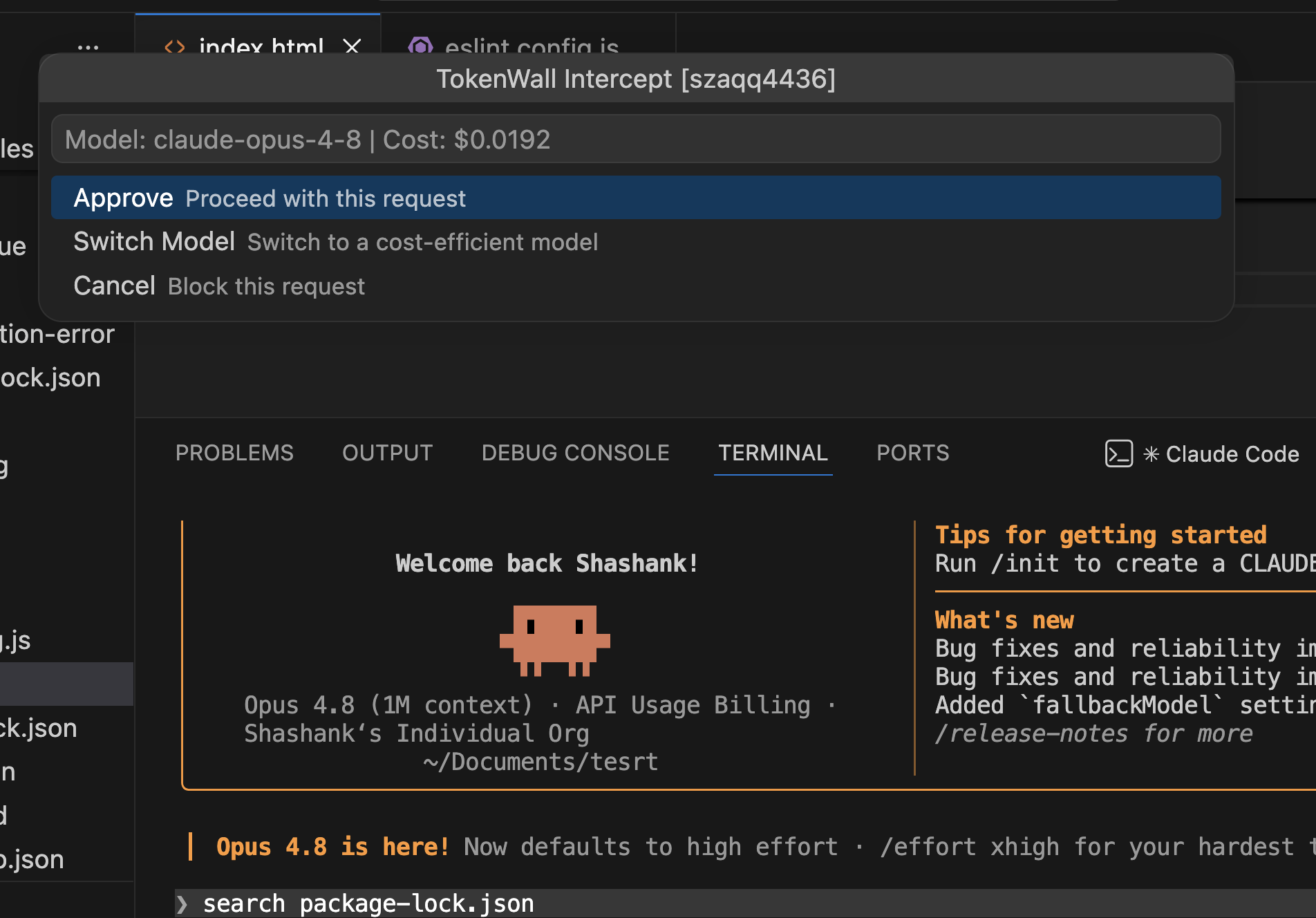
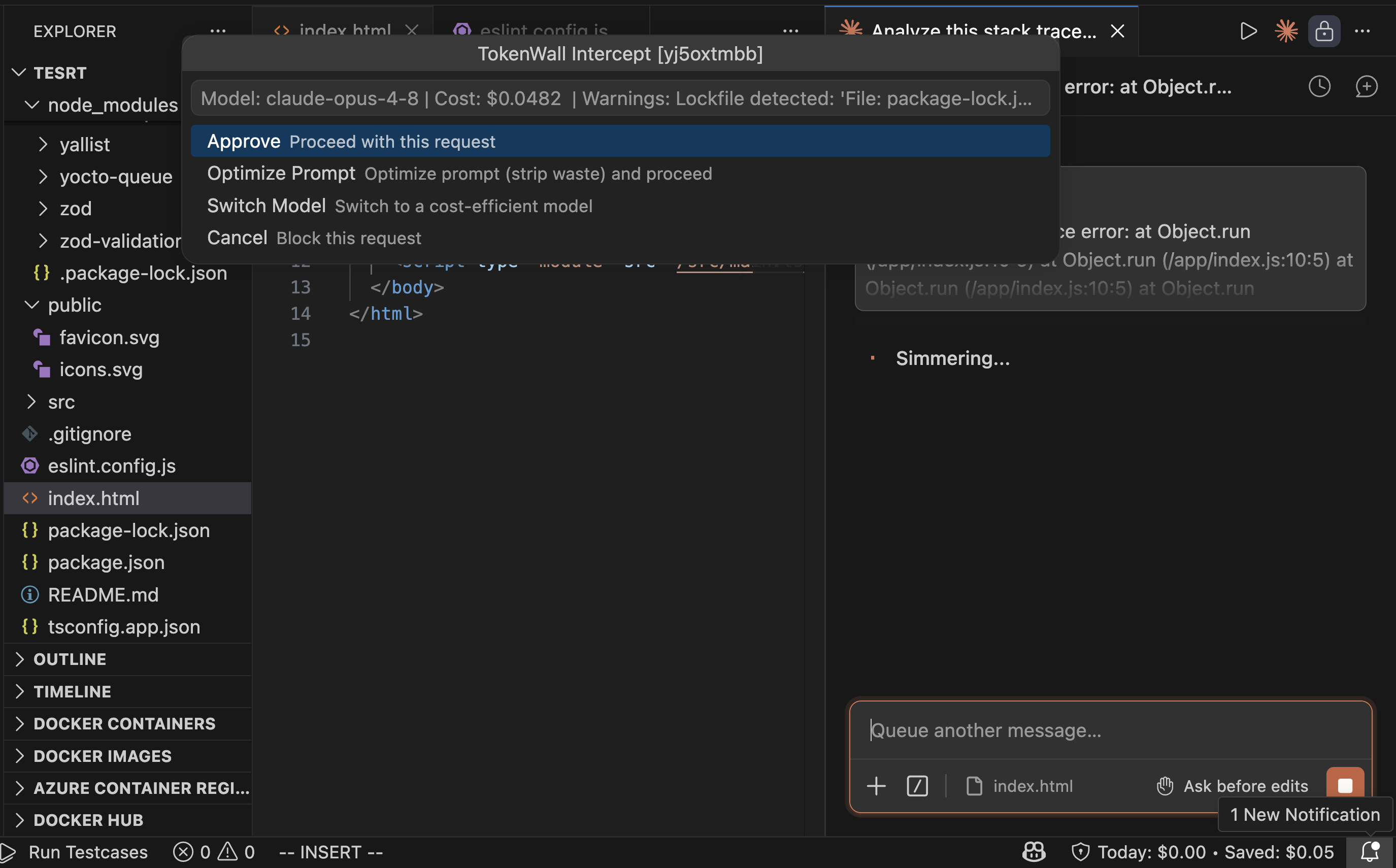
Proxy & Spend Firewall
Intercept downstream LLM requests locally, estimate transaction costs before execution, enforce strict budget guardrails, and prevent runaway AI agent overspending.
$ npm install -g tokenwall